
한땀한땀 정성들인 코딩
페이징, 세그먼테이션 왜 사용할까? 본문
세그먼테이션은 왜 쓰고
페이징은 왜 쓸까?
보호모드에서는 왜 세그먼테이션, 페이징을 모두 쓰고
IA-32e 모드는 사실상 선형주소로 변경하는 과정인 세그먼테이션이 없다.
왜? WHY?
1. 물리 메모리를 물리주소 있는 그대로 사용하는 경우

만약 32bit의 레지스터 크기를 가지고 있으면
0000 0000 0000 0000 0000 0000 0000 0000 ~ 1111 1111 1111 1111 1111 1111 1111 1111 범위의 값을 가질 수 있다.
10진수로 0~4,294,967,295
16진수로 0~FFFF FFFF 이다.
즉, 32bit 레지스터는 2^32개의 숫자를 표현할 수 있다.

메모리의 주소는 위 그림처럼 byte단위로 접근한다. (주의 : bit 단위가 아니다.)
즉, 32bit 레지스터는 2^32(표현할 수 있는 숫자의 개수) x 1byte(CPU의 메모리 접근 단위) = 4,294,967,296byte(메모리 용량)이 된다.
* 4,294,967,296byte는 4GB이다.
물리주소만을 사용하고 CPU가 32bit 레지스터를 가지고 있으면 4GB까지 메모리 인식이 가능하다.
- 인텔 CPU에서 주소를 가리키는 32bit 레지스터는 EIP이다.
- 32bit 윈도우의 최대 메모리 인식 용량은 4GB이다.
2. 리얼모드에서 세그먼테이션
세그먼테이션은 메모리를 목적에 따라 구분하기 위해 나왔다. 명령어가 작동하는 코드와 말그대로 데이터가 있는 영역을 나눈다고 보면 된다.
리얼모드에서 물리주소는 세그먼트 레지스터 x 16 + 범용 레지스터 이다.
레지스터는 모두 16bit 이므로 0 ~ (2^16-1)의 숫자를 표현할 수 있으며, 개수는 2^16이다.
세그먼트 하나의 크기는 범용 레지스터에 있는 주소값이 가리킬 수 있는 범위이므로, 2^16 x 1byte
= 65536byte(=64KB)가 된다.
즉, 세그먼트 레지스터와 범용 레지스터를 조합해서 나타낼 수 있는 주소의 범위는
표현할 수 있는 전체 범위는 (2^16-1)(세그먼트 레지스터의 최대값) x 16 + (2^16-1)(범용 레지스터 최대값)
= 0xF FFF0 + 0xFFFF
= 0x10 FFEF
= 1,114,095
이다.
다시말해, 메모리의 크기는 최대 1,114,095 x 1byte = 1,114,095byte(=1.06248MB) 이다.
- 두 개의 레지스터를 조합하면 1.06248MB까지 사용할 수 있지만 인텔 CPU에서 리얼모드에서는 실제로 최대 1MB 까지 사용할 수 있다.
- 세그먼테이션은 접근 권한을 설정할 수 있기때문에, 메모리 접근 제어를 위해서 사용하기도 한다.
3. 보호모드에서 세그먼테이션만 사용
보호모드는 인텔의 32bit 모드이다.
보호모드에서 세그먼테이션은 세그먼트 레지스터가 물리주소를 바로 나타내지 않는다. GDT를 거치게 되어있다.

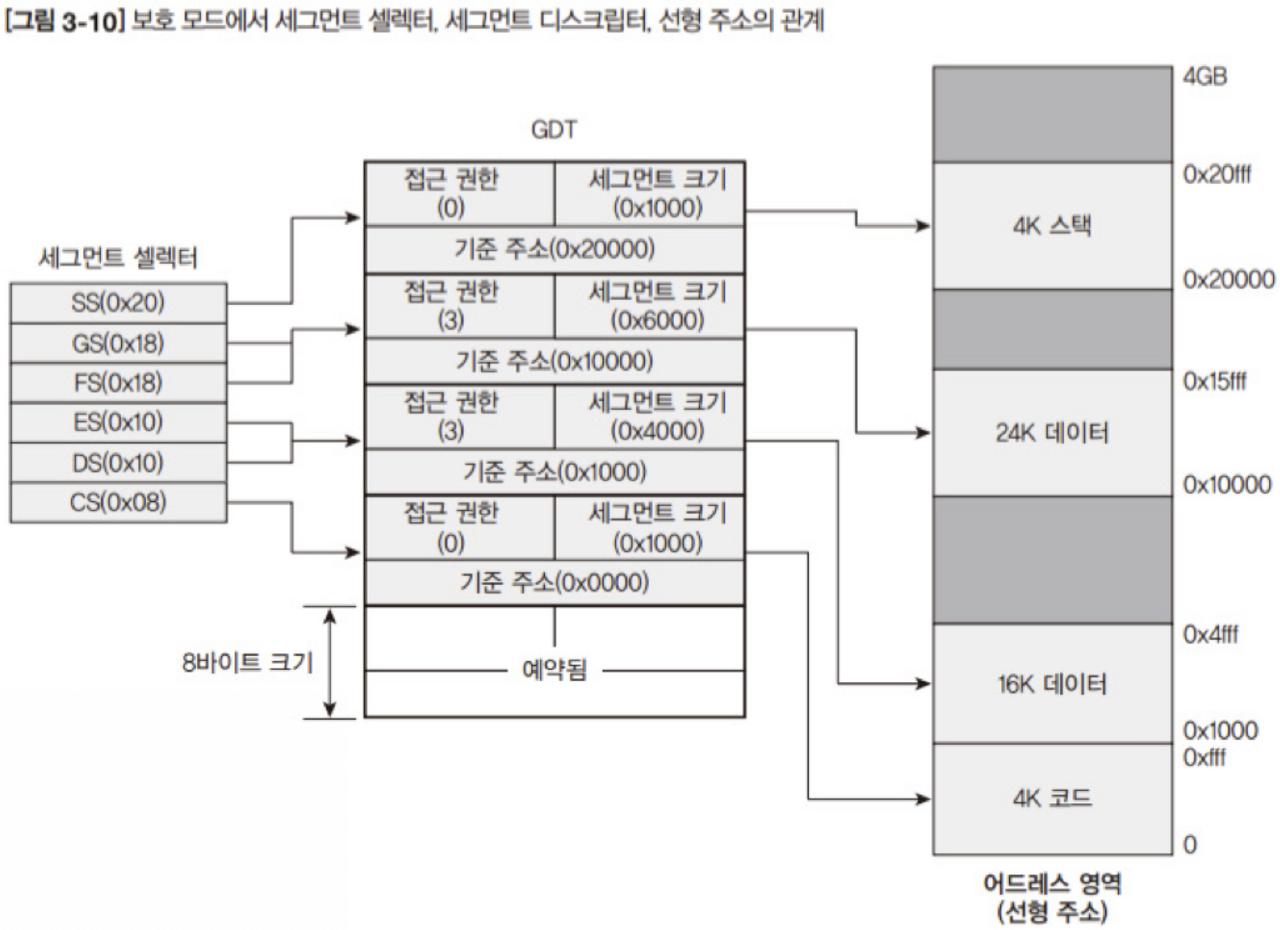

세그먼트 크기를 GDT에서 정의하므로 고정되어 있지 않다.
GDT에서 32bit크기를 가진 기준주소(Base)와 16bit 범용 레지스터를 조합하여 선형주소를 표현한다.
* 리얼모드에서 세그먼트 레지스터에 16을 곱하는 과정은 없다.
이론상으로 32bit 크기를 가진 기준주소와 16bit 범용 레지스터 사용하면 2^32byte + 2^16byte = 4GB + 64KB 까지 선형주소를 가질 수 있다.
즉, 보호모드에선 4GB + 64KB 까지 메모리 인식이 가능하다.
- 근데 저런 애매한 크기를 가진 메모리가 세상에 있을까?...
* 주소를 나타내는 값을 확장 할수록 가상 메모리 크기를 크게 잡을 수 있다.
4. 보호모드에서 페이징만 사용
페이징을 안쓰고 세그먼테이션만 쓴다고 해서 아래문제가 있지는 않다.
1. 내부 단편화 문제가 발생한다. X
- 세그먼테이션은 가변적으로 메모리를 할당하는 기법이다. 필요한만큼만 세그먼트 단위로 메모리를 할당하기 때문에 내부단편화가 없다.
- 외부단편화는 있다.
2. 다중 프로세스가 돌아가는 환경을 구현하기 어렵다. X
- 페이징 기법에서 CR3 레지스터를 변경해서 동작하는 프로세스를 봐꾸는 것처럼, 세그먼테이션에서도 GDTR만 변경하면 되기 때문에 구현가능하다.
3. 세그먼트의 하드디스크 Swap이 불가능하다. X
- GDT는 세그먼트가 메모리에 존재하는지 나타내는 P flag가 있다. 가능하다.
4. 메모리 접근제어가 어렵다. X
- 세그먼테이션의 GDT, 페이징의 페이지테이블 모두 접근 제어를 위한 비트가 있다.
5. 물리 메모리 크기(2GB)보다 더 큰 가상 영역을 사용할 수 없다. X
- 세그먼트를 Swap하면 되기 때문에 가능하다.
6. 응용프로그램끼리 메모리를 공유할 수 없다. X
- 세그먼트 단위로 공유하면 가능하다.
그럼 페이징을 왜 쓸까?
1. 외부 단편화가 없어진다. O
- 페이징은 고정적으로 메모리를 할당하는 기법이다. 메모리에 사용할 수 없는 비는 공간이 없기 때문에, 외부단편화는 없다.
- 내부 단편화는 있다.
* 보통 외부단편화로 인한 낭비보다 내부단편화로 인한 낭비가 작다.
- 세그먼테이션에서 외부 단편화로 인한 낭비는 최대 세그먼트의 최대 크기(=2^16 x 1byte=64KB)이다.
- 페이징에서 내부 단편화로 인한 낭비는 페이지의 크기다. (페이지의 크기는 64KB보다 작게 설정 가능하다.)
페이징을 쓰든 세그먼테이션을 쓰든 아래문제는 똑같이 존재한다.
1. 물리 메모리 크기(4GB+64KB)보다 더 큰 가상 영역을 사용할 수 있다. X
- 보호모드 세그먼테이션은 물리메모리 4GB+64KB까지 사용가능하다.
- 보호모드 페이징은 선형주소가 32bit이기 때문에 물리메모리 4GB까지 사용가능하다.
5. 보호모드에서 세그먼테이션 & 페이징
그럼 페이징만 쓰면 안될까? 왜 세그먼테이션이랑 같이쓸까?
- 세그먼테이션이 지원하는 기능이 페이징에서 모두 가능한데 굳이 왜쓸까?
- 그래서 실제로 리눅스에서는 세그먼테이션을 안쓴다. 아니 정확히는 있으나 마나한것으로 만든다. intel CPU에서 세그먼테이션은 강제되어 있기 때문에 모든 세그먼트의 시작선형주소를 0, 마지막선형주소를 4GB-1로 만든다.
* IA-32e모드에서의 세그먼테이션 동작방식과 동일하다. 있으나 마나한것을 만듬.
* 리눅스 GDB에서 EIP레지스터에 들어가는 값은 논리주소가 아니라 선형주소다.

IA-32e모드에서는 GDT의 세그먼트 크기(Limit), 기준 주소(Base)를 모두 무시하므로 선형주소의 범위가 제한되지 않는다.
근데 보호모드에서는 세그먼트 크기(Limit)가 20bit인데 마지막 선형 주소를 어떻게 4GB-1로 만든다는 걸까?
Flags에 있는 G비트(granularity)를 설정하고 Limit을 0xFFFFF로 최대값으로 설정하면 선형주소의 범위를 4GB까지 확장할 수 있다.
- Limit: A 20-bit value, tells the maximum addressable unit, either in 1 byte units, or in 4KiB pages. Hence, if you choose page granularity and set the Limit value to 0xFFFFF the segment will span the full 4 GiB address space in 32-bit mode.
결론
- 보호모드 리눅스는 세그먼테이션을 사용하지 않는다. (정확히는 의미가 없게 만든다.)
- 리눅스에서 EIP에 들어가는 값은 선형주소다. (논리주소가 아니다.)
- EIP는 32bit 크기를 가졌기 때문에, 보호모드 리눅스는 최대 4GB까지 물리메모리 인식이 가능하다.